etcd یک پایگاهدادهی key-value توزیعشده و با کارایی بالا است که برای ذخیره دادههای حیاتی کوبرنتیز استفاده میشود. در کوبرنتیز، etcd نقش source of truth را ایفا میکند و تمام اطلاعات مربوط به وضعیت cluster (مانند وضعیت nodes، pods، configurations و غیره) را ذخیره میکند.
وظایف اصلی etcd در کوبرنتیز شامل موارد زیر است:
State Management: ذخیره وضعیت جاری و desired state برای هماهنگی بین control plane و اجزای مختلف.
Leader Election: پشتیبانی از فرآیندهای انتخاب رهبر (leader) برای هماهنگی در سیستمهای توزیعشده.
Configuration Management: ذخیره تنظیمات پیکربندی که توسط API Server کوبرنتیز خوانده و نوشته میشوند.
پایداری و دسترسی بالا (High Availability) در etcd بسیار مهم است، زیرا از دست دادن دادههای etcd میتواند به از دست رفتن اطلاعات کل cluster منجر شود. برای این منظور در سرویس کوبرنتیز ستون، به طور خودکار از etcd نسخهی پشتیبان (backup) گرفته میشود.
کامپوننت etcd از کامپوننتهای مدیریتی کوبرنتیز است که در سرویس کوبرنتیز ابری ستون، توسط ستون نگهداری و بهینهسازی میشود. کاربر نیز میتواند با تنظیم مانیتورینگ و موارد مشابه از کیفیت نگهداری این کامپوننت در کلاستر، اطمینان حاصل کند.
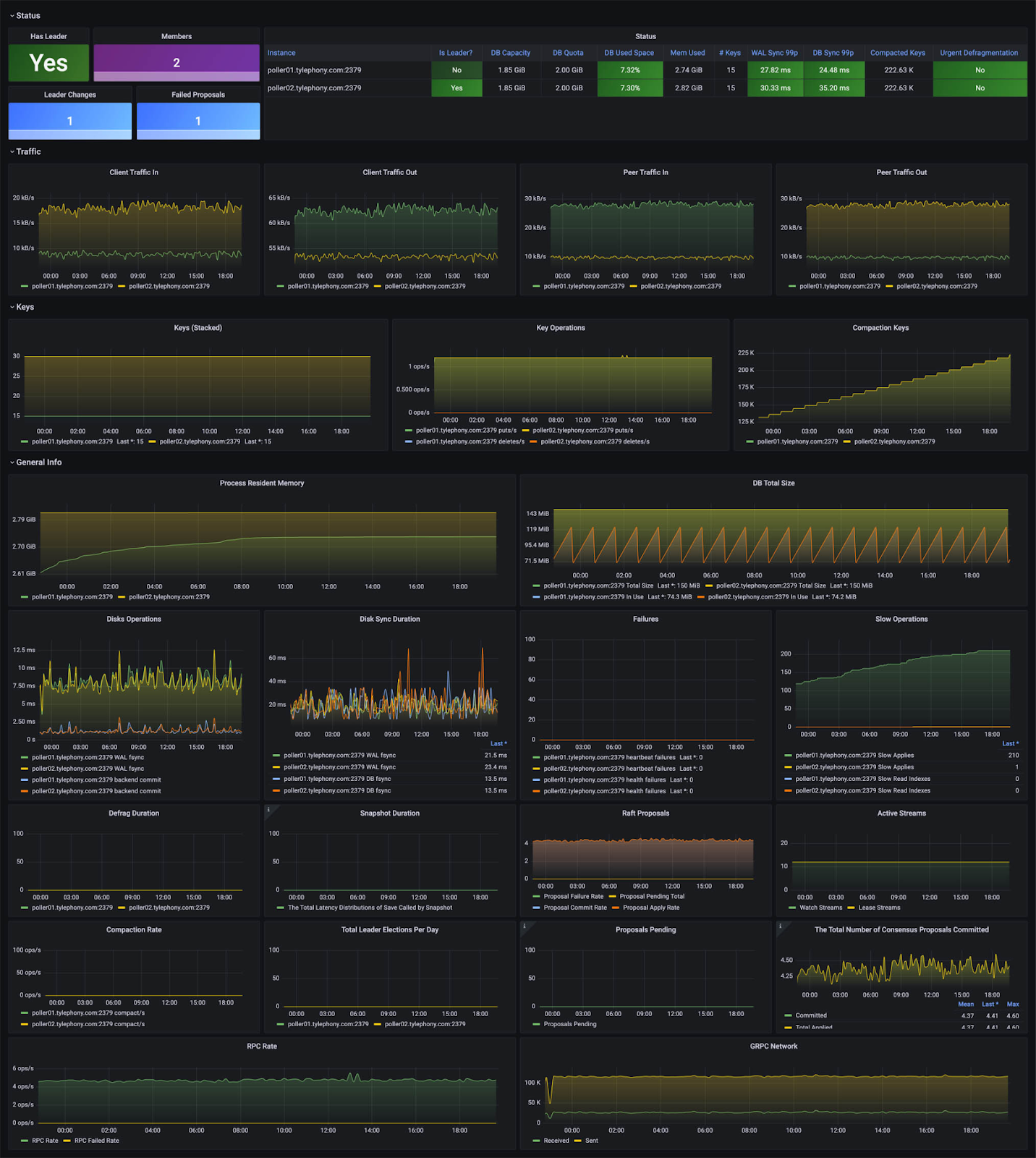
سایز دیتابیس ETCD
دیتابیس etcd برای اینکه قابل اتکا باقی بماند، نیاز به نگهداری دورهای دارد. این نگهداری معمولاً به صورت خودکار و بدون خرابی یا کاهش عملکرد توسط خود etcd انجام میشود و منابع ذخیرهسازی مصرف شده توسط etcd را مدیریت میکند. مقدار ماکزیمم حافظه که etcd استفاده میکند توسط فلگ quota-backend-bytes محدود میشود. این مقدار در ابتدا به طور پیشفرض توسط etcd برابر با ۲ گیگابایت تنظیم میشود. همچنین حداکثر اندازهی پیشنهادی etcd برای این مقدار 8 گیگابایت است و برای جلوگیری از جابجایی یا تمام شدن حافظه، ماشین باید حداقل به این اندازه مموری داشته باشد.
اگر یکی از اعضای etcd منابع بیشتری که از مقدار quota تعریف شده مصرف کند، یک هشدار (alarm) ایجاد میشود که etcd را در حالت تعمیر و نگهداری با عملیات محدود قرار میدهد. برای جلوگیری از پر شدن فضا، تاریخچه فضای کلید etcd به صورت خودکار توسط خود etcd فشرده (compact) میشود.
راهاندازی مانیتورینگ برای etcd
مانیتورینگ etcd برای اطمینان از سلامت و عملکرد کلاستر بسیار مهم است. این راهنما دستورالعملهای گامبهگام برای تنظیم مانیتورینگ etcd و بررسی روشهای مختلف برای انجام این کار را ارائه میدهد.
گام ۱: دسترسی به سرتیفیکیتهای etcd
۱- یافتن پاد etcd
ابتدا پاد etcd را در کنترل پلین شناسایی کنید.
kubectl get pods -n kube-system
به دنبال پادی با نام مشابه <etcd-node-name> بگردید.
به http://localhost:9090/targets بروید و اطمینان حاصل کنید که تارگت های etcd بهصورت UP ظاهر میشود.
گام ۴: استفاده از Grafana
۱- وارد کردن داشبورد etcd
یک داشبورد آماده etcd را از جامعه Grafana وارد کنید. به Dashboards > Import بروید و ID داشبورد را وارد کنید یا فایل JSON را آپلود کنید. به طور مثال می توانید ازاین دشبورد آمادهاستفاده نمایید.